Model Training to Deployment ft. LuciferML and TrueFoundry. (1 of many,….More coming soon)
These days we are faced with many ML use cases that not only need the branching and testing of the ML pipeline. Therefore, we must not only make crucial decisions regarding the solution, but we must also put the trained model into production. Understanding how the model was produced, why one model was chosen over others, and replicating it is all important since these models are becoming increasingly important in commercial services and commodities.
Many people don’t know how to deploy a model in production; if they do, they aren’t aware of the means and mediums for deployment.
Thankfully with the advancements in recent Technologies, we now have access to various platforms that helps us not only in Experiment Tracking but deploying Model in Production.

One is TrueFoundry which provides the fastest post-model pipeline framework for Data Scientists (DS) and Machine Learning Engineers (MLEs). TrueFoundry launched MLFoundry. TrueFoundry’s client-side library for logging experiments, models, metrics, data, functions, and predictions. It also allows for the monitoring of model endpoints in 15 minutes. With MLFoundry, you can track experiments with a few lines of Code, compare and visualize experiments on a rich dashboard, and log experiment artifacts. As a result, you can identify factors that influence performance, solicit feedback, and share experiments with teams to facilitate collaboration.
Let’s write the Code.
1. Introduction
We will use LuciferML, an AutoML Library, for Creating the models. LuciferML’s purpose is to take away all your hassles and does all the hard work for you. It’s currently in the development stage. Preprocesses and Trains different models on your Data.
For Experiment Tracking and Model Deployment, we will use TrueFoundry, the MLOps platform that helps deploy a model in less than 15 mins.
2. About Dataset
This Dataset is from Kaggle. It has 10 columns from which we are going to predict “Potability” column
3. Importing Libraries
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.style.use('dark_background')
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
from tqdm import tqdm_notebook
import plotly.graph_objects as go
import plotly.express as px## Importing LuciferML
from luciferml.supervised.classification import Classification
from luciferml.preprocessing import Preprocess as prep## Importing TrueFoundry's Helpers
import mlfoundry as mlf
import servicefoundry.core as sfy'import warnings
warnings.simplefilter(action='ignore', category=Warning)
4. Loading Dataset
dataset = pd.read_csv('../input/water-potability/water_potability.csv')5. Starting EDA
a) Data Preview

b) Describing Data

c) Visualization for Target Distribution


5. Data Preparation
Dividing the data into Features and Labels
features = dataset.iloc[:, :-1]
labels = dataset.iloc[:, -1]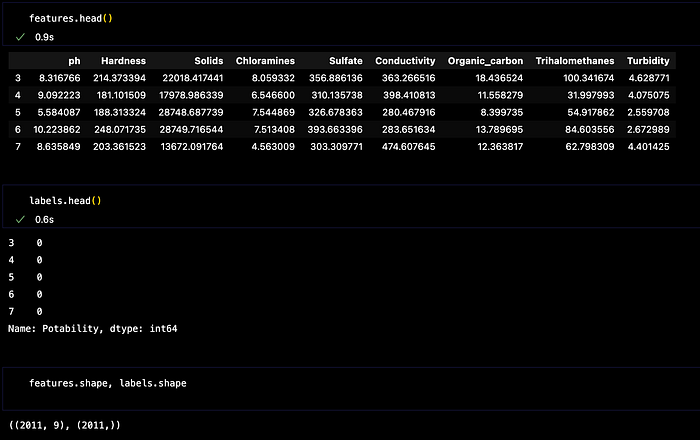
6. Training LuciferML
In this use case, I trained over 17 Models using LuciferML, of which Random Forest Classifier performed the best.
params = {'criterion': 'gini', 'max_features': 'auto', 'n_estimators': 150,'random_state':42}
classifier10 = Classification(predictor = 'rfc',params=params, smote = 'y')
classifier10.fit(features, labels)
result = classifier10.result()
accuracy_scores[result['Classifier']] = result['Accuracy']Output:
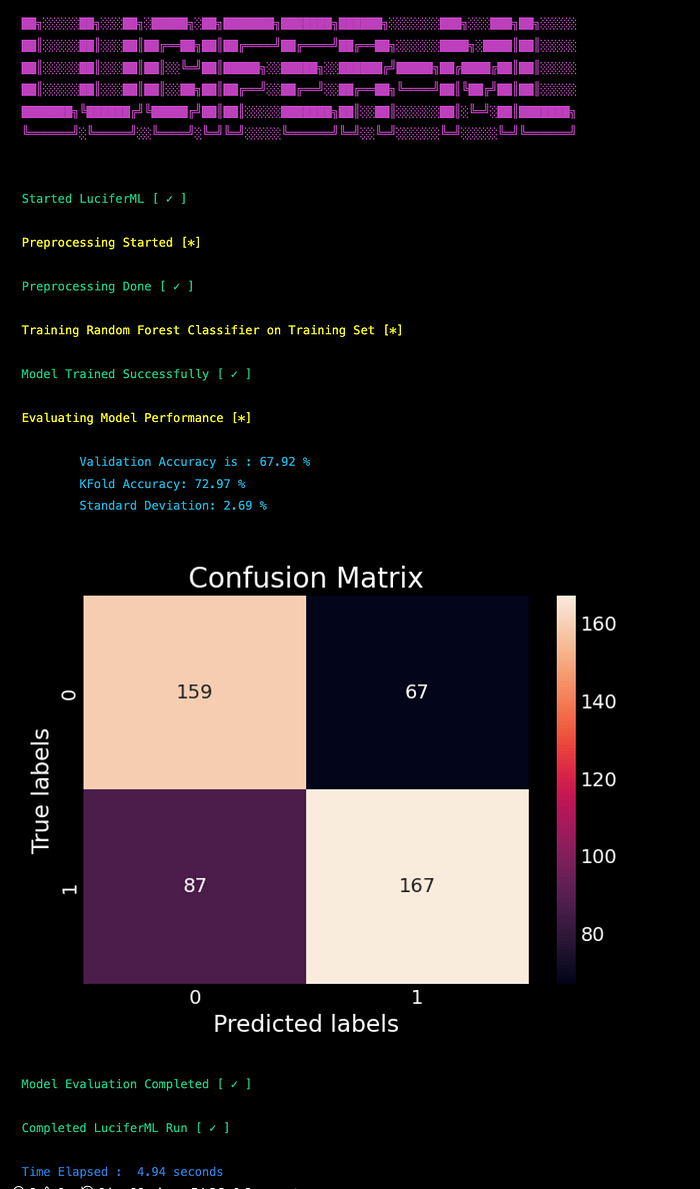
6. Accuracy Comparison Among Multiple Models and saving Best Model

path = classifier10.save()Output:

7. Now comes the best part for which we all are here……Experiment Tracking and Deploying Model
Here, we will use TrueFoundry for our MLOps needs.
a) Logging to TrueFoundry using ServiceFoundry Core and your API Key
You can get your API Key from here
sfy.login(api_key)b) Creating New Project Named Water using MLFoundry
mlf_api = mlf.get_client(
api_key=api_key)
mlf_run = mlf_api.create_run(
project_name='water', run_name='water-best-model-3')
c) Capturing Metrics
metrics = {
'K_Fold_Accuracy': classifier10.kfold_accuracy,
'Val_Accuracy': classifier10.accuracy,
}
mlf_run.log_metrics(metrics)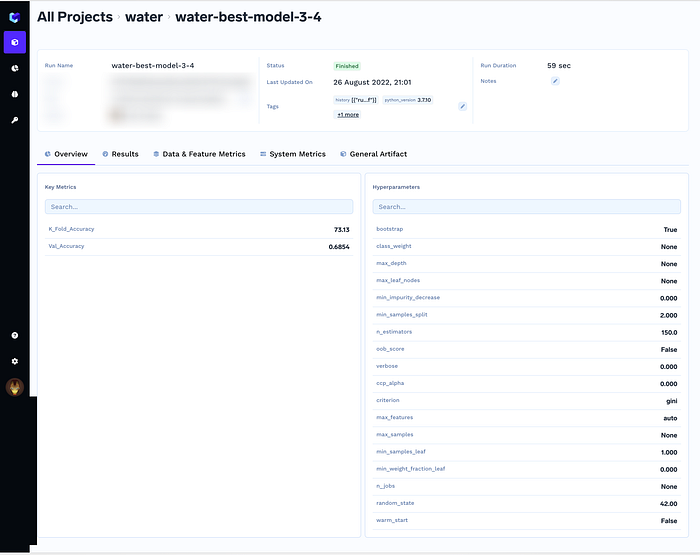
d) Capturing Model and its Artifacts
mlf_run.log_params(classifier10.classifier.get_params())save_paths = {
'Model': path[0],
'Scaler': path[1]
}
mlf_run.log_artifact(path[0], 'Model_Path') #Logs Artifacts
mlf_run.log_artifact(path[1], 'Scaler_Path')mlf_run.log_model(classifier10.classifier, "sklearn") # Logs Models
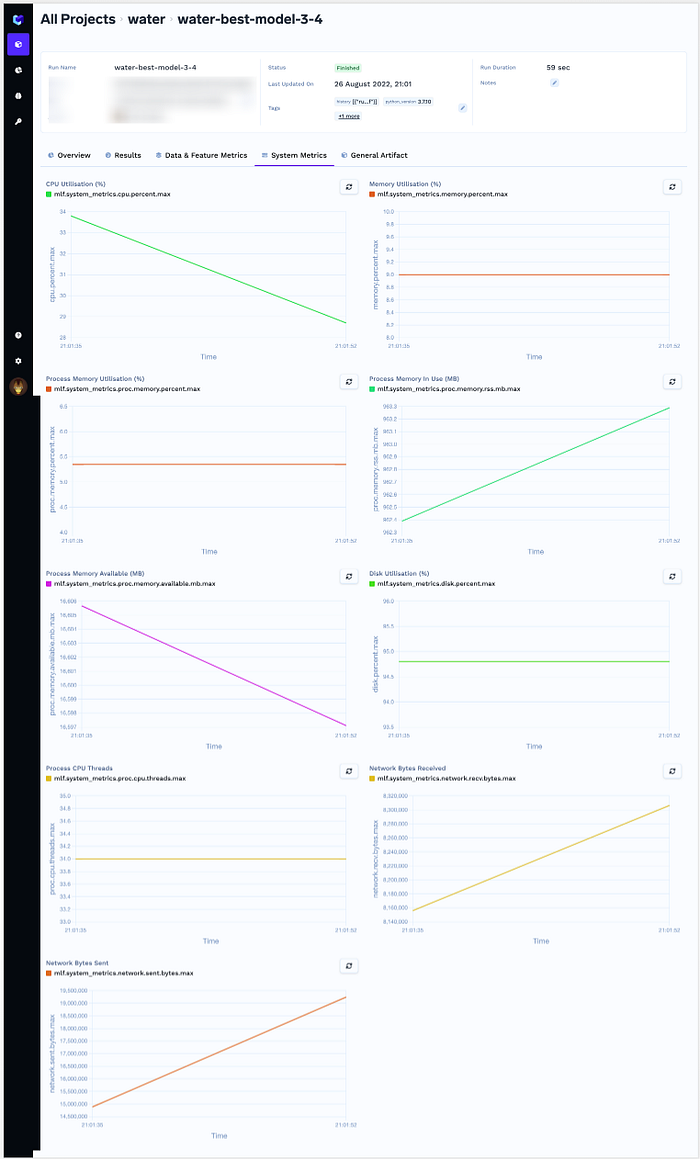
e) Capturing Dataset
mlf_run.log_dataset("features", features)
mlf_run.log_dataset("labels", labels)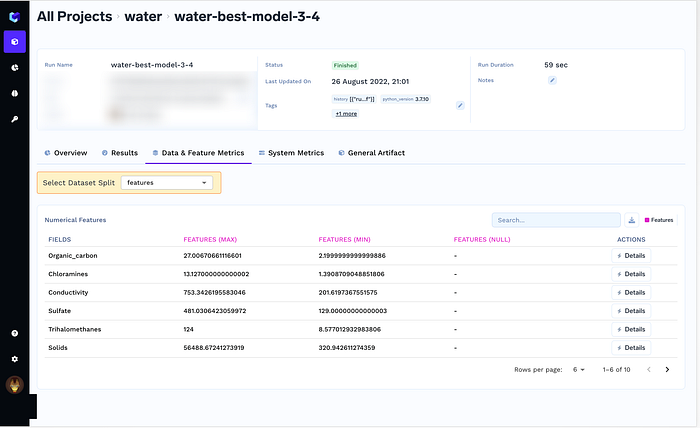
f) Deploying Model on Gradio using TrueFoundry
%%writefile deploy.py # Magic function to write this code to deploy.py fileimport mlfoundry as mlf
import gradio as gr
import pandas as pd
import numpy as npmlf_client = mlf.get_client(
api_key=api_key)runs = mlf_client.get_all_runs('water')run = mlf_client.get_run(runs['run_id'][0])
model = run.get_model()df = run.get_dataset('features')df = pd.DataFrame(df.features)inputs = []
i = 0
sample = df.iloc[0:1].values.tolist()[0]
for x in df.columns:
if df[x].dtype == 'object':
inputs.append(gr.Textbox(label=x, value=sample[i]))
elif df[x].dtype == 'float64' or df[x].dtype == 'int64':
inputs.append(gr.Number(label=x, value=sample[i]),)
i += 1
def predict(*val):
print(val)
global model
if type(val) != list:
val = [val]
if type(val) != np.array:
print('conv')
val = np.array(val)
print(val.shape)
if val.ndim == 1:
print('reshape')
val = val.reshape(1, -1)
pred = model.predict(val)
return pred.tolist()[0]
app = gr.Interface(fn=predict, inputs=inputs,
outputs=gr.Textbox(label='Potability'))
app.launch(server_name="0.0.0.0", server_port=8080)
# Gathering Requirements
requirements = sfy.gather_requirements("deploy.py")
reqs = []
for i, j in enumerate(requirements):
reqs.append('{}=={}'.format(j, requirements[j]))
with open('requirements.txt', 'w') as f:
for line in reqs:
f.write(line)
f.write('\n')# Deployment
service = Service(
name="water-service-3",
image=Build(
build_spec=PythonBuild(
command="python deploy.py",
),
),
ports=[{"port": 8080}],
resources=Resources(memory_limit="1.5Gi", memory_request="1Gi"),
)
service.deploy(workspace_fqn=workspace)And Voila our Model is Deployed now
You can see all your deployed services here
The model is Deployed Here: https://water-service-3-arsh-dev.tfy-ctl-euwe1-develop.develop.truefoundry.tech
Video:
Code:
The above Code is also present in this Kaggle Notebook
Summary
In this post, we learned how with a very minimal code, we can train a lot of ML Models using LuciferML, Tracked Model’s Artifacts, and Deploy those Models with TrueFoundry
